
Las soluciones a las que lleguemos pueden ser tan inteligentes como las bases sobre las cuales las construimos.
Desde el inicio de los tiempos, las ciencias han acompañado al ser humano, quien impulsado por la lógica y la razón que lo caracterizan, ha logrado avances significativos en este campo tan amplio y complejo. Sin ir tan lejos, podemos evidenciar la creatividad y el ingenio humano en un hecho tan simple (aparentemente) como construir un objeto redondo y ponerlo a rodar, tal invención combina ciencias como la física y las matemáticas.
Y es que a medida que la humanidad ha ido avanzando, las ciencias se han ido desarrollando de tal manera que se han convertido en el motor evolutivo del hombre en la sociedad, un gran reflejo de ello son todos los avances tecnológicos que ya hacen parte de la cotidianidad.
En años recientes con el auge de la inteligencia artificial, hemos visto como las máquinas han sido capaces de aprender y analizar información, el desarrollo de estas capacidades es conocido en las ciencias de la computación como Machine Learning – ML. Así pues, el objetivo de este artículo es explicar cómo en este momento de la humanidad, las matemáticas continúan jugando un papel protagónico (aunque se tenga poca conciencia de ello), en la implementación de procesos asociados a Machine Learning.
¿Cuáles son las matemáticas que componen el machine Learning?
Generalmente, se tiene la concepción que para construir modelos de machine learning basta con utilizar aquellos que se encuentran en librerías, con lenguajes de programación predeterminados y que sólo requieren de la acción de introducir la información necesaria.
Lo anterior es totalmente incorrecto, ya que, primero se debe saber qué información es relevante para el correcto funcionamiento de un modelo, pues como dice un conocido dicho dentro de este campo «basura entra, basura sale», y segundo y más importante, no conocer los fundamentos de estas herramientas generalmente, termina en alternativas que al final no van a solucionar ningún problema.
Por tal razón a continuación, desarrollaré los fundamentos a los que hice referencia anteriormente:
Algebra lineal
Vectores, ecuaciones lineales, matrices todos estos conceptos son claves dentro del Machine Learning, y obligatoriamente deben conocerse, pues de entrada nos encontramos soluciones donde operaciones cíclicas como un For o While son reemplazadas por operaciones entre matrices, con el fin de buscar eficiencia al realizar estos cálculos, si seguimos avanzando encontramos representaciones de objetos en espacios vectoriales, temas complejos como el análisis de componentes principales (PCA siglas en inglés), en donde a través de operaciones matriciales y proyección de vectores, podemos reducir las características dentro de un análisis.

Ejemplo de una operación entre matrices – Machine Learning
¿De qué manera se aplica al mundo real?
Para dar claridad a lo anterior tomemos como ejemplo el campo de la psicología de la personalidad; todos tenemos diferentes personalidades y estas tienen diferentes matices, alguien se puede parecer mucho a otra persona en unos aspectos, pero a su vez diferir completamente en otros. ¿Existe alguna manera de cuantificar esto?
Desde hace aproximadamente 100 años se ha intentado dar respuesta a esta pregunta, con resultados que, si bien no acaban de abarcar toda la magnitud de esta incógnita, si han podido representar de manera parcial la personalidad de un ser humano.
Ahora cabe aclarar que dichas interpretaciones siempre se han realizado a través de criterios cualitativos, pero ¿será posible representar la personalidad de alguien de una manera cuantitativa? Para ello tomaremos como referente principal, la hipótesis léxica cuya idea principal se basa en que cualquier rasgo de la personalidad de un individuo siempre debe corresponder a una palabra del idioma, por ejemplo, una persona es valiente, sensible o tímida.
En un principio, psicólogos que se dedicaron al estudio del tema, encontraron alrededor de 4500 palabras que describían los diferentes rasgos humanos, más adelante profesionales de la misma rama se dieron a la tarea de agrupar dichas palabras hasta reducir la cifra a 500. ¿Pero qué ocurre si experimentalmente tomamos estas 500 palabras y les aplicamos PCA?
Lo que obtenemos es la reducción de estas 500 características a 5 rasgos con los cuales se puede clasificar la personalidad de un individuo (extroversión, responsabilidad, neocriticismo, cordialidad y apertura a la experiencia), dichos rasgos son conocidos en psicología como el modelo de los 5 grandes. Una muestra del porque el álgebra lineal jamás pasará de moda.
Cálculo diferencial, integral, multivariado
Implícito en los otros temas matemáticos necesarios para entender sobre machine learning, resulta bastante útil conocer sobre integrales y derivadas parciales al momento de revisar las funciones de optimización, o para hallar matrices Hessianas, con las cuales podemos encontrar la convexidad de una función, esta característica es muy importante debido a que nos ayuda a elegir o descartar dicha función, así como a su vez para hallar sus puntos mínimos, lo que se traduce a la respuesta más óptima que podemos hallar en dicho procedimiento. Esto también es conocido como un híper parámetro, una variable dentro de una función que a medida que es ajustada hace que el modelo que estamos generando mejore o empeore.

Ilustración de una matriz de correlación
Hay que tener en cuenta que cuando hablamos de entrenar modelos, estamos hablando de analizar cantidades gigantes de información, acción que supone tiempo y costos elevados de procesamiento, por lo que responder a preguntas como: ¿cuál será ese número mágico que debemos colocar en nuestro híper parámetro, que hará que nuestro modelo funcione a la perfección?, a través del instinto y experiencia no es suficiente. Se debe conocer la teoría sobre cómo funciona el modelo que estamos aplicando para de esta manera tener la certeza de que lo que estamos haciendo tiene sentido y no hay nada mejor que el cálculo para respaldar este tipo de decisiones.
Estadística y probabilidad
Gran parte de los modelos generados a través del machine learning son o conllevan elementos estadísticos y probabilísticos, de esta manera los conocimientos sobre teoría de probabilidad, combinatorias, teoría de conjuntos, ley de Bayes entre los más relevantes, sirven de aliados para enfrentarnos a los diversos problemas que se nos planteen.
Un ejemplo de lo anterior se ve en los árboles de decisión, una técnica muy popular dentro del ML cuyas raíces están en el teorema de la probabilidad condicional. De la misma manera encontramos las máquinas de soporte vectorial que en palabras coloquiales se pueden definir como algoritmos clasificadores, cuyas respuestas están sustentadas en la probabilidad de que un punto pertenezca a una u otra clase, dentro de un espacio vectorial.

Descripción gráfica de un árbol de decisión
Se han preguntado alguna vez de qué manera funciona la predicción del clima o las predicciones demográficas. La respuesta es modelos de series de tiempo, que no es más que la aplicación de
diversos métodos estadísticos tales como estimaciones de tendencias, cálculo de estacionalidad, análisis de correlaciones, entre los más destacados, para un conjunto de datos que se han medido en diferentes etapas del tiempo y están ordenados de manera cronológica. Así sin duda alguna nos podemos referir a la estadística y probabilidad como el núcleo del ML.
Optimización
El concepto matemático para optimización está basado en unos criterios de selección y un conjunto de elementos, el reto está en hallar el elemento que mejor se ajuste a dichos criterios, siempre teniendo en cuenta la eficiencia del proceso y el uso de recursos, no es lo mismo encontrar un resultado exacto gastándose 3 días en encontrarlo y la capacidad de 10 servidores, a hallar un resultado no tan exacto, pero en 10 minutos y con un solo servidor.
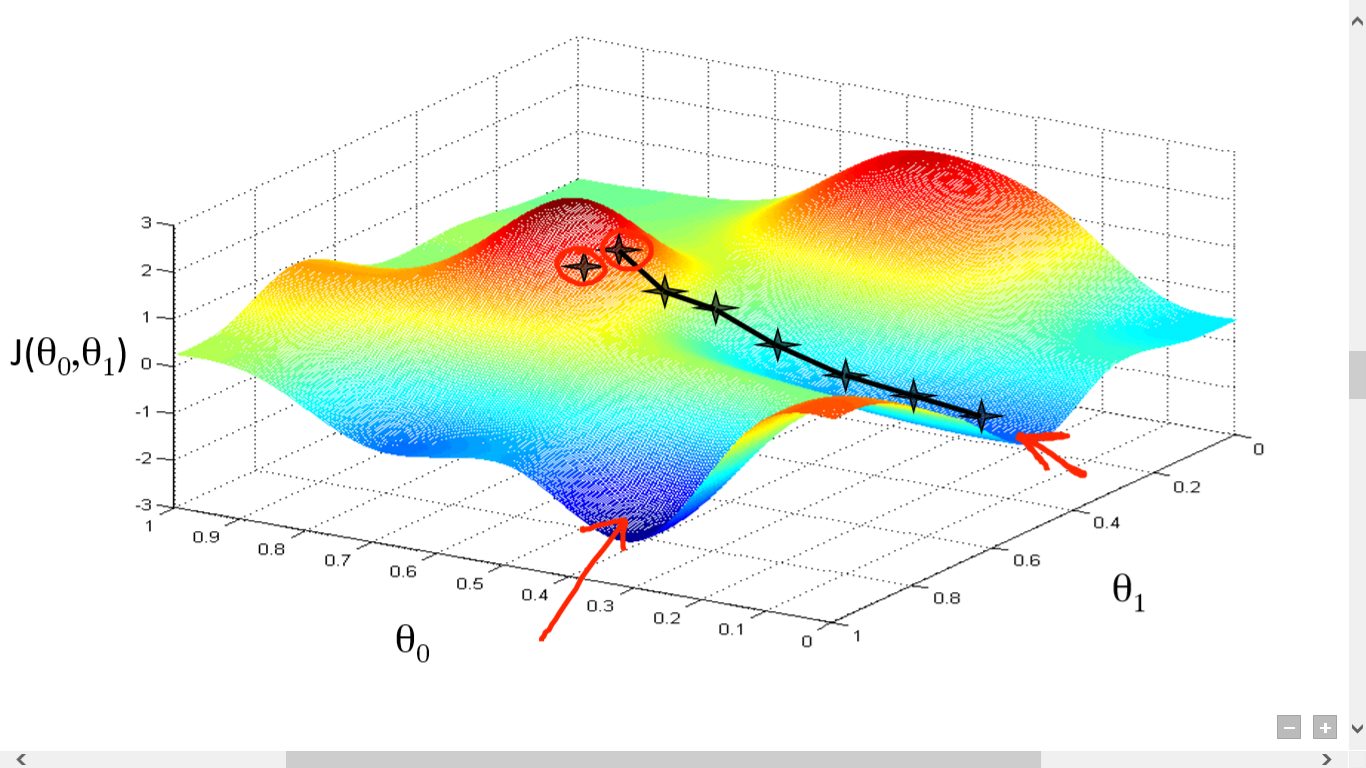
Un claro ejemplo de este tema se da en el Gradiente Descendiente el cual es un algoritmo que aplica técnicas de optimización para encontrar un valor mínimo local dentro de una función. Explicado de una forma sencilla , suponga que usted está caminando en una montaña y de repente la niebla cubre el ambiente, en ese momento, su único objetivo es bajar la montaña para encontrar la planicie, así que precavidamente y paso a paso usted empieza a bajar hasta que en un punto encuentra terreno plano, en este escenario su mínimo local sería el terreno plano, su función seria bajar de esa montaña y el gradiente seria usted mismo pues es quien va recorriendo toda la montaña para encontrar el punto plano.

Explicación de la operación del gradiente descendiente
¿Cómo podría empezar a aprender del tema?
El principal problema que enfrentan la mayoría de las personas que quieren aprender de este campo tan interesante de la AI, es la gran cantidad frentes de acción que tiene, lo que se traduce en aprender sobre conceptos nuevos, herramientas nuevas, temas que a primera vista parecen enredados, pero que en la medida en que se conozcan sus bases, se hacen más sencillos de entender.
Así que, desde un punto de vista más personal, y como recomendación lo mejor es empezar por la raíz de todo, la estadística y probabilidad, para tener un acercamiento a los tipos de problemas que nos enfrentaremos, de allí podremos continuar con un repaso de algebra lineal, la cual me resulta
divertida pero no deja de ser desafiante, siguiendo nuestra hoja de ruta estaría todo lo relacionado con cálculo, tener claros conceptos básicos de derivadas, integrales y dimensiones es lo primordial para así finalizar con optimización que como ya lo vimos anteriormente tiene por dentro álgebra lineal y cálculo.
Conclusión
Conocer los fundamentos matemáticos del machine learning, nos ayuda en el día a día a resolver cuestiones que son clave dentro de nuestra labor, como, por ejemplo: seleccionar el algoritmo que más se ajuste a nuestro problema, escoger los híper parámetros que mejor se ajustan a nuestro modelo, identificar problemas en los modelos como sesgos o sobre entrenamiento, hallar una función óptima para resolver nuestro problema, entre las tareas de gran relevancia.
Es por lo anterior que este tema es indispensable para alguien que está interesado en aprender de ML. Hay que recordar que, a grandes rasgos estamos intentando construir tecnología capaz de emular tareas y comportamientos humanos, y si no sabemos cómo estamos construyendo estas tecnologías, lo más probable es que las soluciones a las que lleguemos sean tan inteligentes como las bases sobre las cuales las construimos.



{kind=link}