MongoDB es una base de datos distribuida, basada en documentos (tipo documental), siendo una de las soluciones más comunes en NoSQL (término acuñado a aquellos repositorios de datos diferentes a las tradicionales bases de datos relacionales).
El concepto ‘schemaless’, es un término que quizás no se ha definido con precisión y que por ende ha generado diversas interpretaciones en el contexto de los desarrolladores.
Schemaless
Cuando se hace un primer acercamiento a MongoDB, usted se encontrará con el concepto ‘schemaless’, interpretado como la falta de estructura y control sobre el almacenamiento de datos y a su utilización en bases de datos relacionales, donde expresa de forma concreta reglas de almacenamiento (que puede o no ingresar dentro de una tabla, formatos, longitudes, reglas, etc).
En este escrito busco clarificar este concepto, abordando el significado de esquema en bases de datos relacionales; la estructura en la que se almacenan los datos en MongoDB, para llegar a hablar sobre ‘schemaless’; y finalmente cómo se puede tener control sobre los datos en bases de datos como MongoDB.
En una base de datos relacional el esquema está definido por un conjunto de tablas cuya estructura, valga la redundancia, se encuentra en un formato tabular. Al crear una tabla se predefine de manera rígida el conjunto de columnas, su tipo de dato, restricciones y su integridad referencial. Un ejemplo de creación de una tabla se representa en la siguiente imagen:
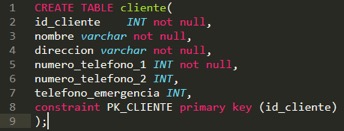
En esta tabla los campos numero_telefono_2 y teléfono_emergencia son opcionales, lo que indica que en un registro pueden o no encontrarse estos valores. Un par de registros de esta tabla podrían ser los siguientes:
| Id | Nombre | Dirección | telefono_1 | telefono_2 | telefono_emergencia |
| 1 | Pepito | Calle 1 | 387222777 | 0387754891 | 3281597538 |
| 3 | Alberto | Calle 2 | 387222666 |
Ahora hablemos de MongoDB donde sus datos son almacenados en documentos con formato JSON. Un documento JSON está compuesto por un conjunto de llaves y valores. Los valores pueden ser de tipo primitivo como un número o un carácter, o estructuras de datos como arreglos o documentos anidados, observemos un ejemplo:
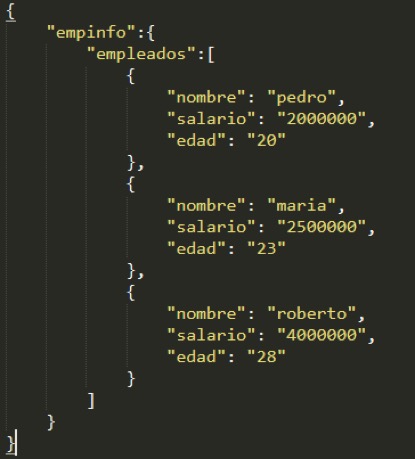
En el documento anterior se observa que la llave “empinfo” contiene un documento como valor, la única llave de este documento se llama empleado, su valor es un arreglo de documentos, dentro de estos documentos se encuentran llaves cuyo valor son tipos primitivos como letras y números.
A partir de esto se puede hacer una analogía de las estructuras que se manejan en MongoDB con las de una base de datos relacional. Y en este orden de ideas, la siguiente imagen ilustra cómo se podrían almacenar los dos registros que fueron insertados en la base relacional dentro de Mongo
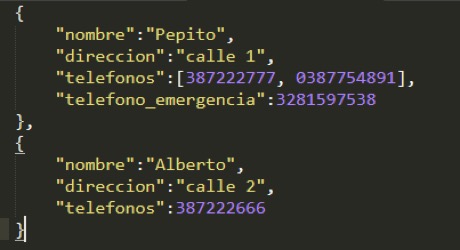
A diferencia de una BD relacional, en ningún momento hubo necesidad de indicar cuál iba a hacer la estructura de los documentos de nuestra colección, esto es lo conocido como ‘schemaless’: En MongoDB no es necesario definir una estructura a nivel de colección, y una llave puede contener diferentes valores en los documentos, como en el caso de la llave telefóno o llegar a ser inexistentes como el caso de la llave telefono_emergencia.
Esta versatilidad es favorable en entornos de desarrollo ágil, dado que la adición de una llave a un documento no implica tener que alterar todos los documentos de la colección, acelerando la implementación de cambios.
Sin embargo, no estandarizar llaves dentro de los documentos de una colección puede llevar a comportamientos no esperados en el aplicativo, por ello se debe definir una estructura base en sus documentos junto a una estrategia para controlar los cambios que se hacen sobre ellos.
Este control se puede implementar desde el código o haciendo uso de herramientas como “schema validation” la cual se encarga de validar los documentos al momento de realizar inserciones o actualizaciones.
Conclusiones
- En MongoDB no existe la definición de un esquema sobre los documentos de una colección, esto favorece el DESARROLLO EN ENTORNOS ÁGILES dado que la adición o eliminación de una llave se realiza a nivel de documento, haciendo que los cambios en ambientes productivos se hagan más rápido.
- Al no haber un esquema a nivel de colección, una llave en los diferentes documentos puede contener valores con diversos tipos de datos o no estar presente, haciendo que el modelado de datos utilice todas las capacidades de los documentos JSON como lo son los documentos anidados o las listas.
- Sin un esquema rígido para todos los documentos de una colección, el correcto funcionamiento del sistema y la integridad y calidad de los datos recaerá en el desarrollador, quien deberá controlar los cambios que se hagan sobre ellos, ya sea por código o utilizando la herramienta “schema validation”.
- Independientemente de que el motor de bases de datos exija o no exija la definición del esquema (estructura), quienes desarrollen el modelo de datos no están exentos de analizar y diseñar dicho esquema que soportará y reflejará la realidad del negocio que se está modelando.