Natural Language Processing o NLP es una rama del conocimiento entre la Inteligencia Artificial y la Lingüística que tiene como objetivo darles la habilidad a las máquinas de entender el lenguaje de los humanos.
NLP involucra el análisis de:
1. Sintaxis: identificar el rol sintáctico de cada palabra dentro de una oración.
Ejemplo: en la oración “Yo compraré dulces.”, yo es sujeto, dulces es objeto directo y compraré es el verbo.
2. Semántica: determinar el significado de las palabras o frases.
Ejemplo: en la oración «El ingeniero fue al cliente», el cliente se refiere a un lugar.
3. Pragmática: establecer como el contexto comunicativo afecta el significado.
Ejemplo: en la oración «David tomó vino en la fiesta. Era rojo». Rojo se refiere al vino que tomó David.
Estos tres análisis los realizamos todos los días, algunos de manera casi inconsciente. Para nosotros, derivar significado del lenguaje resulta ser algo muy sencillo y es consecuencia no solo de un proceso de desarrollo y aprendizaje, sino de evolución de miles de años. Ahora, piense qué tan difícil puede ser para una máquina, que solo entiende unos y ceros, comprender sus emociones al escribir un review de una película o un producto que haya comprado.
Dentro de los retos más difíciles en NLP está enfrentarse a expresiones ambiguas, la pragmática y el uso implícito de conocimiento previo. Algunas oraciones que muestran este tipo de problemas son:
- Estaré de vacaciones solo unos días. ¿Estará de vacaciones solo, o estará de vacaciones pocos días? (Ambigüedad)
- Vimos a Juan paseando. ¿Vieron que Juan estaba paseando, o vieron a Juan cuándo estaban paseando? (Ambigüedad)
- El primer sprint del proyecto se realizó en un mes. El termino sprint entra dentro de un lenguaje técnico en el desarrollo de proyectos. (Conocimiento previo)
Piense qué tan difícil es para una máquina derivar significado de este tipo de oraciones si ni siquiera nosotros mismos podemos derivar significado de manera clara.
¿Pero de qué nos sirve que las maquinas nos entiendan?
El lenguaje es la forma principal que tiene el ser humano para comunicarse de manera efectiva. Piense que usted usa el lenguaje todos los días para poder realizar tareas, hacer análisis, transmitir emociones y muchas otras acciones y necesidades de nuestro día a día. Ahora piense, que pasaría si una máquina que puede hacer tareas y acciones miles de veces más rápido que usted, pudiera comprenderlo, y no solo a usted, sino a miles de personas a la vez.
Es claro que las implicaciones de una máquina que entiende lenguaje natural son muy fascinantes. Acá presentaré algunas aplicaciones y sistemas que hacen uso de NLP.
Dialog Systems
Estos sistemas se dividen en dos grandes grupos: sistemas orientados a tareas y chatbots. Los primeros se centran en cumplir tareas útiles, mientras los segundos se centran en mantener una conversación con el usuario sin necesidad de implementar alguna tarea específica.
La siguiente imagen muestra cómo se dividen este tipo de sistemas según puedan realizar tareas útiles y según puedan mantener una conversación social compleja.
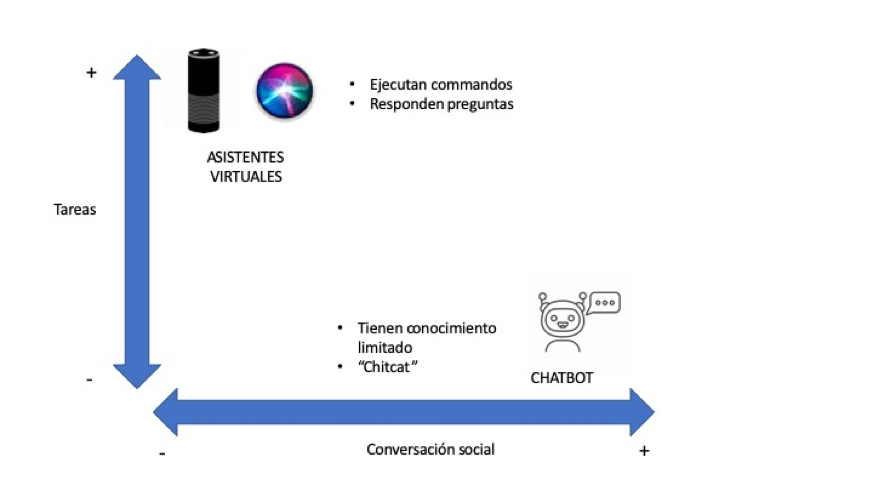
En muchos ámbitos de negocio se suelen confundir estos términos ya que todas las empresas piden desarrollar chatbots, cuando realmente quieren un sistema orientado a realizar tareas.
Ejemplos de sistemas orientados a desarrollar tareas son asistentes virtuales como Siri, Alexa y Cortana. Los chatbots, por otro lado, se caracterizan por tener personalidades definidas, mantener conversaciones completas, y expresar emociones como miedo, malgenio y desconfianza. La tendencia es a movernos hacia asistentes virtuales que tengan personalidad, que puedan manejar conversaciones sociales más complejas pero que a la vez tengan un gran conocimiento en muchos temas y puedan realizar tareas útiles.
Clasificación de textos
Este es el proceso de asignar categorías a textos según su contenido. Cuatro de las aplicaciones más comunes de clasificación de textos son:
- El análisis de sentimiento: cuando se quiere determinar si un texto es negativo, positivo o neutro, o cuando se quiere determinar la emoción predominante en un texto. Esto es muy usado para analizar textos en redes sociales o reviews de productos y servicios.
- La clasificación de textos por tema: cuando el objetivo es entender de qué está hablando un texto dado o cuál es su tema principal.
- Detección de lenguaje: se quiere determinar un texto dado en qué lenguaje está escrito.
- Detección de intención: es muy usado en servicio al cliente para clasificar las respuestas de los clientes según su intención (interesado, no interesado, cancelar suscripción, posible comprador…)
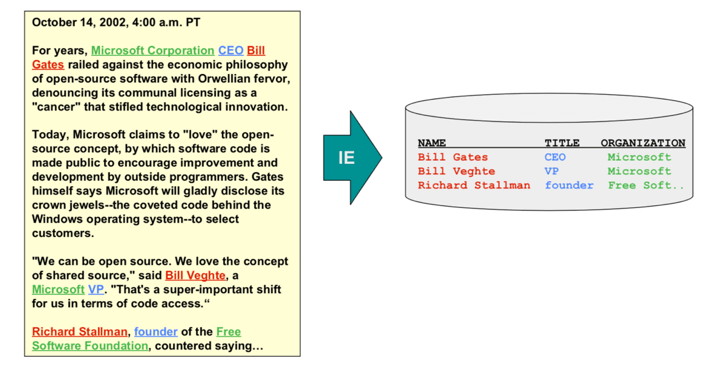
Extracción de información
Este es el proceso de transformar información no estructurada en datos estructurados. El objetivo es encontrar entidades importantes dentro de un texto (las entidades pueden ser personas, organizaciones, locaciones, …), descubrir las relaciones entre ellas y almacenarlas en una estructura de datos como un base de datos relacional. Esto tiene como propósito estructurar la información de una manera en la que se puedan realizar mejores análisis, se pueda reutilizar la información y se puedan generar mejores insights.
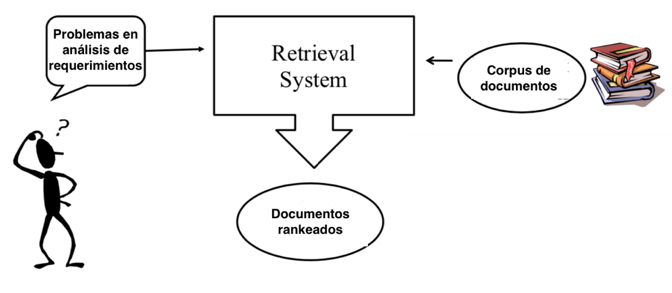
Information Retrieval Systems
Information Retrieval es la ciencia que está detrás de los motores de búsqueda. Tiene como objetivo traer información relevante a los usuarios de fuentes de información no estructurada como textos, imágenes, videos y audio. El ejemplo por excelencia de este tipo de sistemas es el buscador de Google. Sin embargo, piense en todos los beneficios que puede tener su empresa si tuviera un “Google interno” que pudiera traer información relevante dentro de todos los documentos, reportes, emails y hasta redes sociales según un criterio de búsqueda que puede ser escrito tal cual usted se expresa normalmente.}
¿Y cuál es la “magia” detrás de esto?
Todos estos sistemas y aplicaciones de NLP están basados en métodos de Machine Learning que parecen a simple vista muy sofisticados. ¿Pero qué tan inteligentes son estos sistemas? Para responder esta pregunta, primero hay que entender qué está detrás de estos sistemas. En general, no hay una convención o un proceso definido para atacar este tipo de proyectos, sin embargo, acá enunciaré tres tareas que suelen ser fundamentales en muchas aplicaciones de NLP.
La primera, es hacer el POS Tagging (Part of Speech Tagging), que tiene como objetivo asignar una etiqueta a cada palabra dentro de una oración según su rol sintáctico.
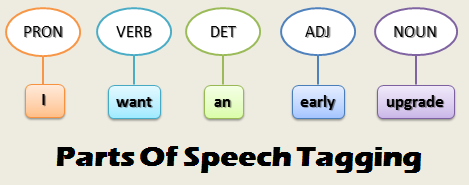
La segunda, es hacer el Dependency Parsing, cuyo fin es analizar la estructura gramatical de una oración estableciendo relaciones entre las palabras.

La tercera, es hacer el Named Entity Recognition, que tiene como fin encontrar todas las entidades relevantes dentro de una oración. Estas entidades pueden ser personas, organizaciones o lugares.
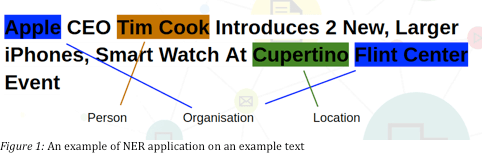
Estas tres tareas son desarrolladas automáticamente por modelos de Machine Learning. Parece casi “mágico” que solo tengamos que pasarles un texto plano a estos modelos para que automáticamente nos hagan estos análisis y tengamos las etiquetas palabra a palabra. Sin embargo, la realidad es que estos modelos no son tan mágicos. Todos estos modelos de Machine Learning son de aprendizaje supervisado, lo que significa que aprenden en base a muchos ejemplos que nosotros los humanos debemos darles. El siguiente ejemplo muestra como un humano debe etiquetar el rol sintáctico de cada palabra (POS tag) en una oración para darle un ejemplo de cómo se hace a la máquina (las etiquetas están en rojo y cada etiqueta tiene un significado):
The/DT grand/JJ jury/NN commented/VBD on/IN a/DT number/NN of/IN other/JJ topics/NNS ./.
¡Note que hay que una etiqueta hasta para el punto final!
Esto es un proceso terriblemente tedioso. Ahora tenga en cuenta que el ejemplo es solo una oración. Para que este tipo de modelos puedan desempeñar automáticamente estas tareas, las máquinas deben aprender de millones de oraciones que, claramente, un pobre humano tiene que etiquetar manualmente. ¿Sigue pareciendo muy sofisticado?
Ya existen enormes cantidades de documentos etiquetados de acceso gratuito, sin embargo, las diferencias en la calidad al etiquetar los documentos, la cantidad de documentos etiquetados y la variabilidad de tipo de documentos etiquetados entre inglés y español son abismales, lo que hace que los modelos de Machine Learning que ejecutan automáticamente estas tareas ya mencionadas sean mucho mejores en inglés que en español.
Lo cierto es que, a pesar de estas limitaciones, se pueden hacer cosas muy interesantes, funcionales y de mucho valor. El reto es entender qué funciona, qué no y porqué, saber usar las herramientas que mejor funcionan, optimizar su uso y tratar de mejorar su desempeño para cada caso específico de negocio.
¿Cuál es el futuro?
El sueño futuro en este campo es llegar métodos que no necesiten de ejemplos humanos o, por lo menos, que se reduzca su dependencia significativamente. Queremos máquinas que no necesiten de millones de ejemplos de oraciones etiquetadas palabra a palabra para aprender.
Ya se sabe que existen métodos que le permiten a las máquinas aprender sin necesidad de tener ejemplos. Estos son los métodos que están detrás de las máquinas que juegan ajedrez mejor que los grandes maestros ajedrecistas, o las que le ganan a los mejores gamers del mundo en algunos video juegos. ¿Pueden estos métodos ser extrapolados a otras áreas de Inteligencia Artificial como NLP? ¿Podemos llegar a máquinas que solo con “observarnos” hablar puedan llegar a comprender lo que decimos?